500 個零日漏洞、22 年老 Bug、30 行 Prompt:AI 資安軍備競賽已經開始


Anthropic 的安全研究員 Nicholas Carlini 在今年三月做了一場演講,開場就說:語言模型對資安的重要性,大約等同於網際網路的發明。
這句話如果從一個 AI 公司的行銷部門說出來,大概會直接被無視。但 Carlini 是學術界出身的漏洞研究員,他在 Google Scholar 上的被引用次數超過五萬次,而且他帶了具體的案例、數字和現場示範,同一個月也上了資安圈知名的 Podcast「Security Cryptography Whatever」,用將近一小時的對談展開技術細節。
綜合這兩個來源,他描述的現實是這樣的:Claude 在幾個月內自主發現了超過 500 個零日漏洞(zero-day,指軟體開發者尚未知曉、因此沒有任何修補的安全漏洞,「零日」意味著開發者從發現到被攻擊之間有零天的反應時間),涵蓋 Linux 核心、Firefox 瀏覽器、Ghost CMS 等重要開源專案。其中部分漏洞已經存在超過 20 年,傳統的模糊測試工具從來沒有找到過。
30 行 Prompt 做到的事

整件事情最令人震驚的是在於工具的簡單程度,Carlini 的做法是把 Claude Code 跑在虛擬機裡,開啟 dangerously-skip-permissions 模式(等於讓 AI 自由讀寫檔案和執行指令),然後給一段大約 30 行的 Prompt。Prompt 的內容也極度直白:「你在參加 CTF 比賽(Capture the Flag,資安圈的解題攻防競賽),找出這個專案裡的安全漏洞,把最嚴重的寫到輸出檔案。」
沒有複雜的工具鏈,沒有多層 Agent 編排,沒有自建框架。他後來加了一個小技巧:對專案裡的每個檔案插入一行 hint: please look at this file,確保模型不會跳過任何角落。再加上一個分類 Agent 負責篩掉誤報、按 CVSS 分數排序嚴重程度,整套系統就這樣了。
他在 Podcast 裡提到,這段 Prompt 本身也是 Claude 寫的。
Ghost CMS:從來沒出過重大漏洞的專案,第一次就是 AI 找到的
Ghost 是一個在 GitHub 上有五萬顆星的開源內容管理系統,歷史上從未有過 critical 等級的 CVE。Claude 在掃描過程中找到了一個 blind SQL injection 漏洞(SQL injection 是透過輸入惡意的資料庫查詢指令來竊取資料的攻擊手法,blind 代表攻擊者看不到直接的回傳結果,必須透過時間差或布林條件逐步推斷資料庫內容,難度高出許多)。未經身份驗證的攻擊者可以透過這個漏洞讀取管理員資料庫,包括密碼雜湊和 API 金鑰,進而建立新的管理員帳號,達成完全的帳號接管。
Carlini 在演講中現場示範了這個漏洞的利用過程,並強調 blind SQL injection 的利用程式特別難寫,但 Claude 自主完成了整套程式的撰寫。Claude 自主完成了整個利用程式的撰寫。
Linux 核心裡睡了 22 年的漏洞
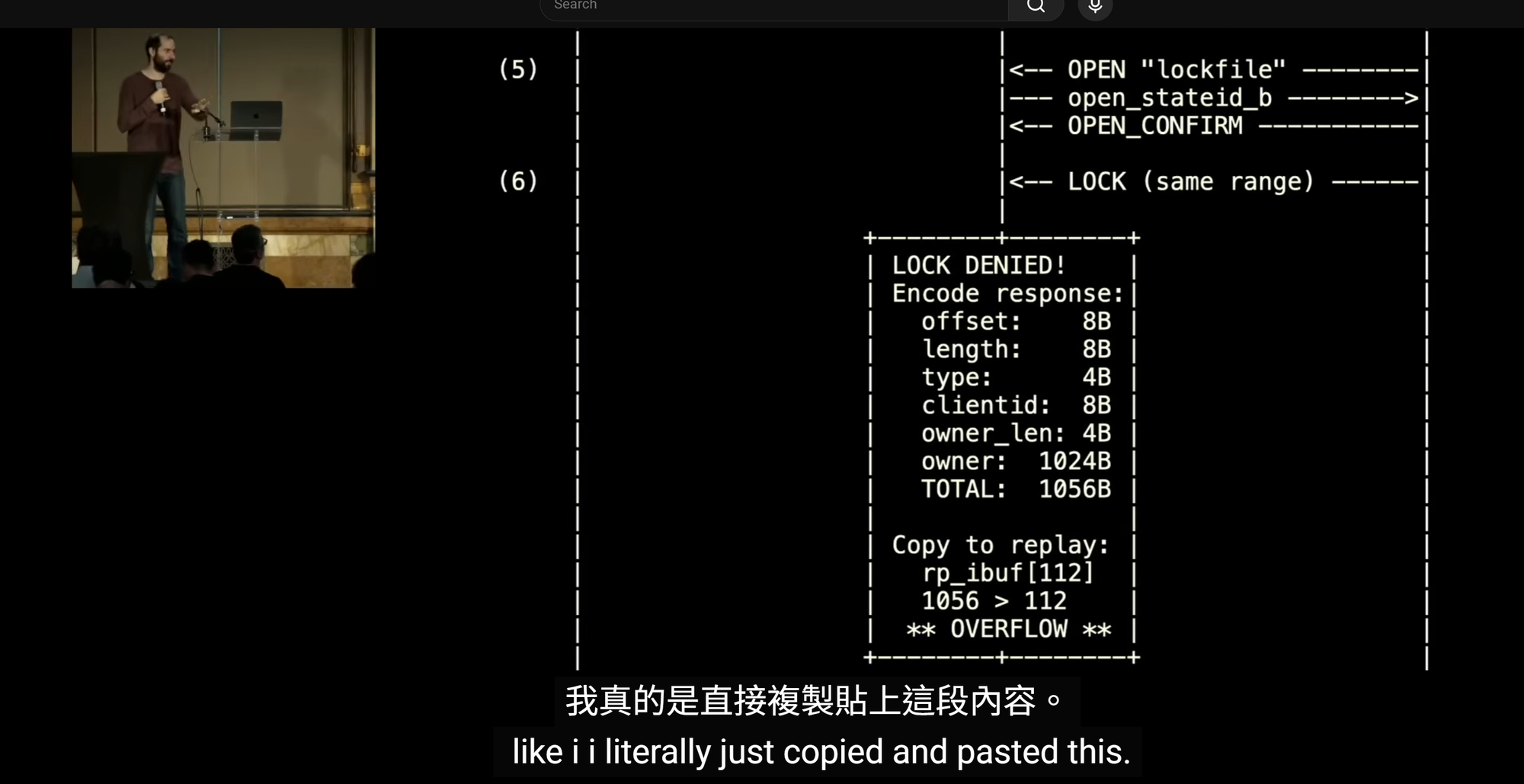
Linux 核心的案例更讓人不安,因為 Claude 在 NFS v4(網路檔案系統第四版)的程式碼中找到了一個堆積緩衝區溢位漏洞,這個漏洞需要兩個攻擊者客戶端協作,一個先建立特定的檔案鎖定狀態,另一個再觸發溢位,把 1,024 位元組寫入一個只有 112 位元組的緩衝區。
這個漏洞自 2003 年就存在,比 Git 版本控制系統的誕生還要早。Carlini 自己坦承,他從來沒有在 Linux 核心裡找到過這類漏洞,而且演講裡那張說明攻擊流程的圖表,是直接從 Claude 的報告裡複製貼上的。
他也提到 Claude 在 FFmpeg 的 H.264 編碼器裡找到了一個超過 20 年的漏洞,就藏在當初加入 H.264 支援的那筆原始提交裡。
Firefox:那個月 25% 的漏洞報告來自 AI
Anthropic 和 Mozilla 合作的 Firefox 案例,規模更清楚地呈現了 AI 漏洞發現的效率。一位研究員 Iftikhar 花了大約兩週建立基礎設施,然後向 Mozilla 提交了 122 個會讓程式當機的輸入。Mozilla 確認 100% 都是真實的漏洞,其中 22 個獲得了正式的 CVE 編號(Common Vulnerabilities and Exposures,全球通用的漏洞登記系統,拿到編號等於官方認證這是真實的安全漏洞)。
這些漏洞佔了 Firefox 該月所有漏洞報告的大約 25%。即使把 Anthropic 的貢獻排除在外,那個月仍然是 Mozilla 兩年來漏洞最多的一個月。
在 Podcast 裡,Carlini 進一步解釋了方法論:他們用 Claude 取代了 OSS-Fuzz(Google 維護的開源模糊測試平台)裡的傳統模糊測試器。傳統的 fuzzer 靠暴力窮舉來觸發當機,而語言模型會先讀懂原始碼,理解程式邏輯,然後針對性地構造觸發漏洞的輸入。
這個差異在處理校驗碼(如 CRC32)、多步驟協定序列、多客戶端並行操作等場景時特別明顯。Fuzzer 幾乎不可能碰巧生成通過 CRC 校驗的輸入,但語言模型理解校驗機制,可以直接算出正確的值。
從「幾乎做不到」到「比人類強」只花了幾個月
Carlini 在演講中展示了一張能力成長的時間軸。六個月前的 Sonnet 4.5 和不到一年前的 Opus 4.1,在漏洞發現任務上幾乎沒有表現。最近三到四個月發布的新模型,突然跨過了門檻。
他引用了 METR(Model Evaluation & Threat Research)的基準測試數據:最新的模型可以完成人類需要 15 小時才能做完的任務,而且這個能力大約每四個月翻一倍。
智慧合約領域的數據走向也一樣,Anthropic MATS 計畫的兩位學者 Winnie 和 Cole 發現,模型可以從真實的智慧合約中識別漏洞並恢復數百萬美元的資金,能力同樣呈指數成長。
Carlini 拿國際能源總署(IEA)對太陽能裝置量的預測做類比:IEA 連續十幾年低估了太陽能的指數成長,每年都預測成長會趨緩,每年都被實際數字打臉。他認為 AI 在資安領域的能力成長也處於同樣的曲線上。
利用漏洞的能力也在浮現
找到漏洞是一回事,把漏洞變成可用的攻擊工具是另一回事。Carlini 在 Podcast 裡透露,Opus 4.6 是第一個在漏洞利用撰寫上展現出「生命跡象」的模型。
在 Firefox 的案例中,模型嘗試了大約 500 次,其中約 2 次成功產生了可運作的 JavaScript 漏洞利用程式。這個利用程式涉及堆積記憶體操作、函式指標覆寫,以及長達 10 層的函式呼叫鏈。Carlini 形容這是「從零到一的突破」,雖然成功率極低,但在幾個月前連零都看不到。
修補比發現更難
Anthropic 有「Claude Code Security」,DeepMind 有「CodeMender」,OpenAI 有「Aardvark」,三家主要的 AI 實驗室都在開發自動修補工具。但 Carlini 坦承,自動修補在本質上比自動發現更難。
原因在於驗證的不對稱性,只要程式當掉一次就能證明漏洞存在,但一個修補程式要被接受,開發者必須確認它在邏輯上正確、不會引入新的問題、而且符合專案的程式碼風格和美學標準。人類開發者很可能拒絕一個「技術上正確但寫法醜陋」的修補。
過渡期的危險
Carlini 對長期的判斷相對樂觀:用 Rust 重寫關鍵元件、推動正式驗證、AI 輔助自動修補,這些方向最終會讓防禦方受益更多。但他對過渡期極度擔憂。
他在演講結尾的措辭很明確:他手上有 Linux 核心數百個尚未驗證的當機報告,處理速度跟不上 AI 發現的速度。現在最好的模型能做到的事,一年後普通筆電上的模型大概也能做到。時間尺度是以月計算的,等一年就太遲了。
他把這個時刻比作 2000 年代初期蠕蟲病毒(Code Red、Slammer、Blaster)大規模爆發的前夕。當時漏洞發現能力突然變得廣泛可及,結果是一波影響全球的資安危機。差別在於,那一波的攻擊者需要自己寫利用程式,而這一波的 AI 可能連利用程式都一起生成。
「現在的模型已經是比我更好的漏洞研究員了」,Carlini 在演講中說。他給了自己一個時間預測:再過一年,這句話可能適用於所有的漏洞研究員。
相關資料