Gemini 成功破關寶可夢,但這代表勝過 Claude 了嗎?


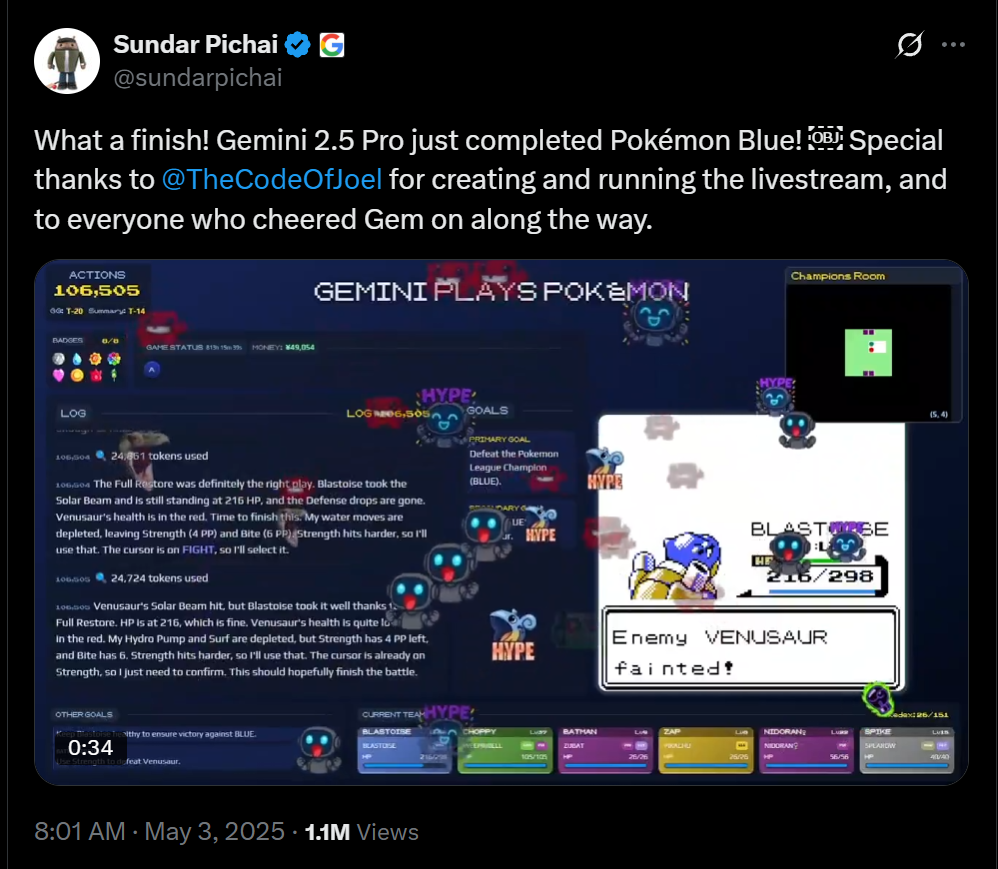
Google 執行長 Sundar Pichai 於 2025 年 5 月 3 日在 X 上分享的消息,他們的 Gemini 2.5 Pro 模型成功地「破關」經典遊戲《寶可夢 藍版》(Pokémon Blue)。畫面顯示,這項挑戰大約花了 106,505 個行動步數達成,最終擊敗遊戲裡的聯盟冠軍。這項成就,連同先前 Google 方面宣稱 Gemini 在寶可夢遊戲中比競爭對手 Claude 更快達到遊戲進度,都引發人們對 LLM 在這類任務上能力的討論。
Anthropic 在介紹其 Claude 3.7 Sonnet 模型時,曾闡述他們為何選擇寶可夢作為一個測試項目。他們認為,就像人類處理問題時會根據難易度投入不同的思考精力一樣,新的模型也具備了「延伸思考模式」和改進的「代理能力」,可以在面對複雜或開放式的任務時,投入更多資源、進行更深入的思考和規劃。
寶可夢這類遊戲,並非簡單的問答,而是一個需要 AI 作為一個「代理人」去感知環境、理解狀態、規劃行動,並在大量的時間步驟中持續維持目標的任務。它要求 AI 不斷地接收遊戲畫面(視覺輸入)、理解遊戲規則和目標、規劃下一步行動(例如移動、對話、戰鬥),並將思考結果轉換成遊戲操作(按下按鍵)。
Anthropic 認為,這種需要長期專注、環境互動和複雜決策的特性,恰好能測試模型在應對真實世界中需要持續互動和達成開放性目標任務時的潛力。早期的 LLM 可能連遊戲開始的房間都走不出去,而能力的提升則能讓模型嘗試更多策略,並在過程中進行自我改進。因此,寶可夢被視為一個能展現 AI 在長時間、多步驟任務中「維持專注並完成目標」能力的有趣且具有代表性的測試。
從公開的數據來看,Gemini 這次不僅完成遊戲,其總行動步數 (約 10.6萬) 也比先前 Claude 達到其最佳紀錄時 (約 21.5萬) 要少。如果單純比較這些數字,很容易會讓人覺得 Gemini 在玩寶可夢這件事上效率更高、能力更強。
然而,多位參與或關注這些實驗的專家,包括 GeminiPlaysPokemon 專案的負責人 Joel Z 本人,都明確指出,這兩場由 AI 執行的寶可夢遊戲,並非在完全相同的條件下進行的標準化基準測試。這就像讓兩位學生考試,但給予的輔助工具與環境不同,即使最後的成績有差異,也很難直接斷定是誰的能力更強。
關鍵差異在於支撐 Gemini 和 Claude 玩遊戲的「代理程式框架」(Agent Harness)。這套框架是連接 LLM 模型與遊戲環境的橋樑,負責處理輸入資訊(遊戲畫面、數據)、提供輔助工具,並將模型的決策轉換為遊戲操作。
雖然雙方的框架都提供基本功能,例如接收遊戲畫面、存取遊戲數據、轉化按鍵指令等,但具體實作細節卻有顯著不同:
- 資訊呈現方式: Gemini 的框架似乎提供更為友善的輸入資訊,例如在遊戲畫面上疊加詳細的文字標籤,甚至提供文字版的「小地圖」。這對於不擅長直接解析像素化遊戲畫面的 LLM 來說,提供巨大的幫助。
- 輔助工具: 雖然兩者都有路徑規劃工具,但其自動化程度和實作方式可能不同。對於導航能力普遍較弱的 LLM 而言,一個強大的導航輔助工具能大幅提升其遊戲進度。
- 開發階段與人為干預: GeminiPlaysPokemon 專案在進行直播時,仍處於活躍的開發和實驗階段。專案負責人 Joel Z 會在實驗過程中對框架進行調整,甚至在必要時給予模型一些關於遊戲機制而非攻略本身的提示。Claude 的專案在公開展示前也經歷優化過程,但 Gemini 的實驗更多是在「直播」整個開發與測試過程,這也影響實驗的可比性。
Joel Z 本人就謙虛地表示,他認為 Gemini 能走得更遠,很大程度上是得益於「更好的框架」,而非模型本身在「寶可夢能力」上大幅領先。他強調這些實驗不應被視為直接比較兩家模型優劣的基準。
這些實驗同時也顯示出目前 LLM 在處理這類任務時的一些普遍限制。即使有輔助框架,模型仍會花費大量的行動步數在無效的探索、重複的錯誤或困惑的思考上。有專家認為,如果框架提供了過多針對遊戲的「鷹架」(scaffolding),那測試的可能更多是框架設計的優劣,而非模型本身的遊戲理解能力或通用代理能力。理想的 LLM 遊戲基準測試,或許應在盡可能減少針對性輔助或確保輔助條件完全一致的前提下進行。
所以,Gemini 成功破關寶可夢《藍版》,無疑是 AI 代理程式在遊戲任務上達成的一個里程碑式成就。這證明結合強大的 LLM 模型與精心設計的輔助框架,AI 確實能在複雜且需要長期互動的環境中取得顯著進展。然而,我們必須了解由於與 Claude 的實驗在條件上存在諸多差異,單憑這次的成就和帳面數據,並不足以斷言目前 Gemini 在「玩寶可夢的能力」上絕對優於 Claude。
未來的我們在看各種 AI 遊戲挑戰,如果希望作為評估 LLM 能力的有效基準,將需要更加嚴謹的設計,確保各個模型選手在盡可能公平一致的環境與條件下進行測試,我們才能更清晰地看到不同模型本身在理解、規劃和執行複雜任務上的真正實力。
延伸閱讀



