GPUs融化中!從「畫素註解」到「魔法繪師」:ChatGPT-4o圖像技術有多猛?


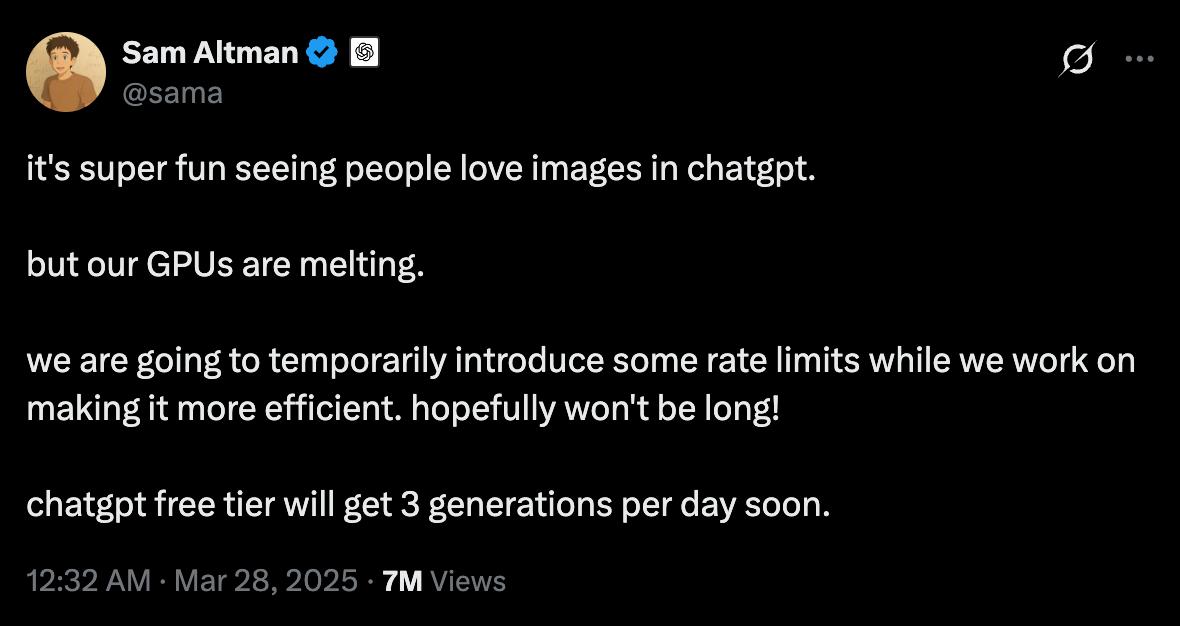
社群媒體上瘋傳著各種以ChatGPT-4o生成的吉卜力風格圖像,熱潮之猛烈,甚至讓OpenAI創辦人Sam Altman在3月28日發推特表示:"看到人們喜愛ChatGPT中的圖像功能真是太有趣了,但我們的GPU正在融化。我們將暫時引入一些使用限制,同時努力提高效率。希望不會太久!"——短短幾天,這則推文已獲得700萬次瀏覽,足見此功能的爆炸性影響。這些作品不僅令人驚嘆於其畫風以及角色連續性,更令人好奇其背後的技術突破。
與此同時 OpenAI 釋出了《GPT-4o系統卡的增補:原生圖像生成》技術報告,首次揭開了這款引爆網路的圖像生成技術的神秘面紗。
報告中的關鍵揭露令人驚訝:與之前的DALL·E系列截然不同,4o圖像生成並非獨立的擴散模型,而是深度嵌入GPT-4o架構中的自迴歸模型。這種根本性的架構差異,讓我們得以一窺AI視覺技術數十年來的演變歷程。
從早期需要人工標記每個像素的繁瑣工作,到如今能自動理解並創造精美圖像的全能模型,這一路徑不僅顯示技術的進步,更代表我們理解智能本質的深刻轉變。本文將帶您了解 AI 圖像訓練方法的演進過程,揭示從語義分割到弱監督學習,再到今日生成式 AI 的技術躍遷。
第一階段:全監督學習與像素級標註
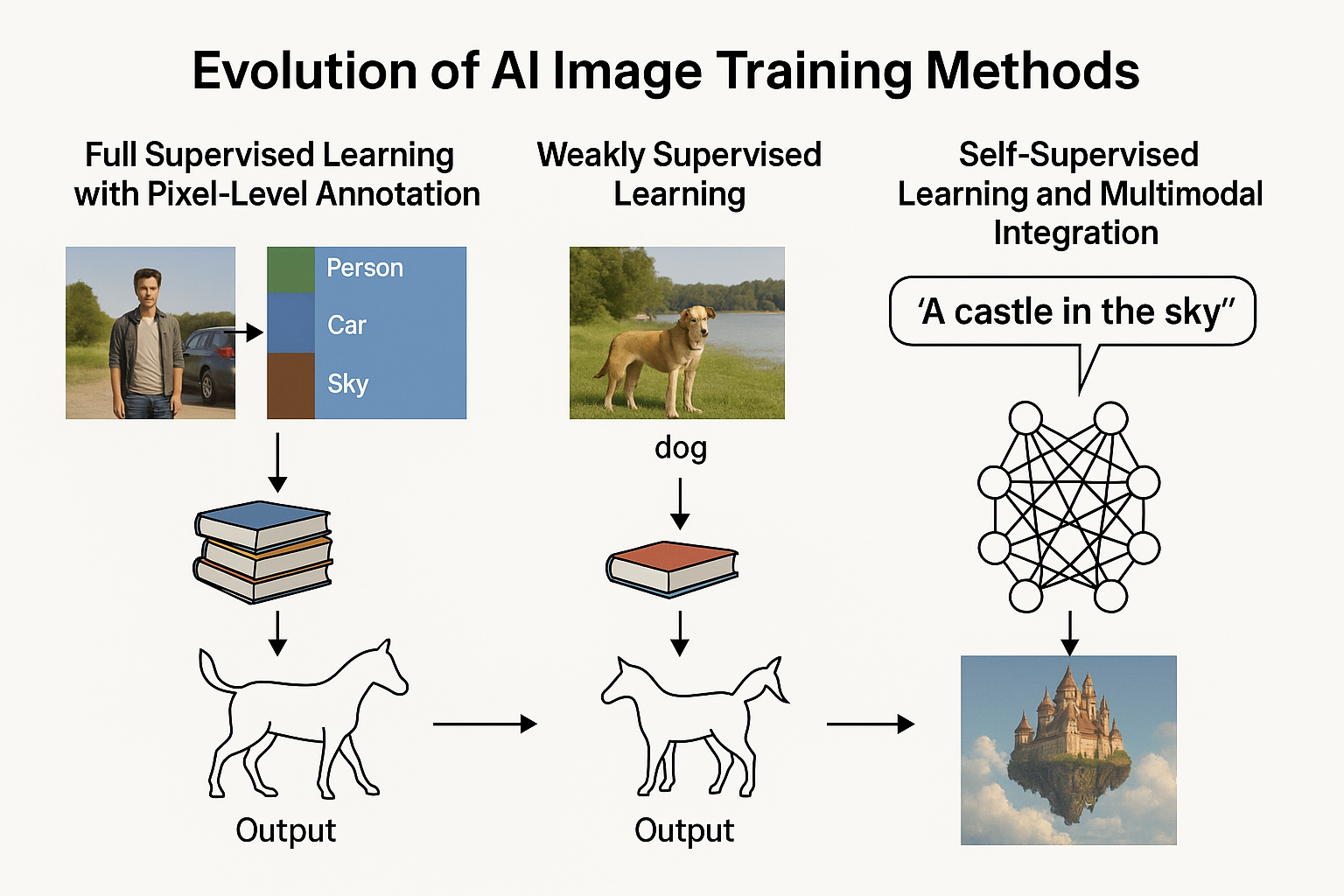
早期的圖像理解始於全監督學習(Fully Supervised Learning)。想像一個簡單的任務:讓計算機分辨出照片中哪些像素屬於「人」,哪些屬於「汽車」,哪些是「天空」。這就是語義分割(Semantic Segmentation)的核心任務。
在這一階段,每張訓練圖像都需要精確的像素級標註:數據科學家需要手工描繪出每個物體的邊界,並為每個區域分配類別標籤。一張普通的1080p圖像包含超過200萬個像素,為數千或數萬張圖像標註這些資訊是一項極其耗時的工作。
這就像是教導一個完全不懂世界的學生,必須指著每個物體解釋:'這是蘋果,這是香蕉',而且必須為每個物體的每個部分都這樣做。這種方法雖然直接有效,但標註成本高昂,限制了可用的訓練數據量,進而限制了模型的學習能力。
第二階段:弱監督學習的突破
隨著研究者意識到全監督學習的局限性,弱監督學習(Weakly Supervised Learning)應運而生。這種方法不再要求精確的像素級標註,而是利用更容易獲取的粗粒度標籤。
弱監督學習就像是從考試答案中學習,而不是從詳細的教科書中學習。在圖像分割任務中,弱監督可能只需要知道「這張圖片包含一條狗」,而不需要標明狗在圖片中的確切位置和邊界。
這一突破極大地降低標註成本,使研究者能夠利用網路上海量的已標記圖像。例如,社群媒體上的照片標籤、電商網站的產品分類都成為了可用的訓練素材。
然而,弱監督學習的挑戰在於如何從這些粗略的資訊中提取精確的知識。研究者開發了多種技術來解決這一問題:
- 多實例學習(Multiple Instance Learning):將圖像視為多個區域的集合,只要其中一個區域包含目標物體,整張圖像就被標記為正例。
- 不完全監督(Incomplete Supervision):只標註部分數據,讓模型自行學習其餘部分。
- 轉移學習(Transfer Learning):利用在相關任務上訓練的模型知識,應用到新任務中。
弱監督學習使我們的視野從"看清每個像素"轉向"理解整體語境",這更接近人類的學習方式。
第三階段:自監督學習與多模態融合
最近幾年,自監督學習(Self-supervised Learning)成為了AI訓練的革命性方法。與前兩種方法不同,自監督學習不依賴人工標註,而是從數據本身創造學習任務。
例如,DALL-E等早期圖像生成模型採用擴散模型(Diffusion Models),通過逐步破壞然後重建圖像來學習視覺特徵。這種方法類似於解拼圖:模型學習如何從噪聲中重建原始圖像,從而理解圖像的結構和內容。
而OpenAI最新的4o圖像生成技術則更進一步,採用了自迴歸模型(Autoregressive Model),並將其原生嵌入到語言模型中。這意味著圖像生成不再是獨立的模塊,而是與語言理解深度整合。
這就像是同時教會AI閱讀和繪畫,而且兩種能力可以相互促進。當AI閱讀"夕陽下的海灘"時,它能立即在"腦海"中"看到"這個場景,類似於人類的認知過程。
這種多模態融合使模型能夠:
- 理解圖文關係,實現更準確的圖像描述和生成
- 進行圖像到圖像的轉換,保留關鍵語義同時改變風格或內容
- 遵循詳細指令,如在圖像中精確添加文字或特定元素
角色一致性:AI圖像生成的新境界
而在OpenAI的技術發展道路上,角色一致性(Character Consistency)已成為評估先進圖像生成模型的關鍵指標。OpenAI 在功能發表時,也在其YouTube頻道發布了「Character Consistency with 4o Image Generation」展示影片,由多模態研究人員David Medina親自演示了這一突破性進展。
Medina首先以一個看似簡單的提示作為開場:「創建一個極度低多邊形的企鵝法師」。他指出,讓傳統模型產生真正低多邊形的輸出並不容易,而GPT-4o卻能準確理解並實現這一需求。這背後正是強大語言模型與圖像生成的深度整合所帶來的理解能力。
更令人驚嘆的是模型在風格轉換中保持角色一致性的能力。當Medina要求將低多邊形企鵝法師轉化為「如同專業人士製作並塗裝的逼真微縮模型」時,GPT-4o不僅保留了企鵝法師的核心特徵(法杖、帽子等),還完美轉換了呈現風格。隨後,他又要求生成「具有光線反射的水晶版本」,得到了同樣出色的結果。
這種能力的突破在於兩個核心優勢:卓越的角色一致性與對使用者意圖的深刻理解。模型不再僅僅字面解析提示詞,而是能夠:
- 識別並保留角色的核心特徵
- 在不同風格和材質間轉換時維持角色識別度
- 理解使用者的高階意圖,而非僅執行表面指令
這一進展代表了圖像生成技術從「文字到圖像的表面映射」向「深度理解與創造」的重要躍遷,也是多模態AI整合的最佳展示。
未來展望:從理解到創造的跨越
GPT-4o的圖像生成能力代表了AI訓練方法從「理解」到「創造」的根本性跨越。從早期需要精確標註每個像素的語義分割,到如今能夠根據文字描述生成逼真圖像的全能模型,AI的學習方式越來越接近人類的認知過程。
最令人驚嘆的是,現代AI不只是記住訓練數據,而是在某種程度上理解視覺世界的基本規則。它們能夠創造出前所未見的圖像,展現出對視覺概念的深度理解能力。
David Medina的企鵝法師演示揭示了這一技術的巨大應用潛力。在遊戲開發領域,設計師可以先創建角色原型,再利用GPT-4o快速生成該角色在不同環境、材質或藝術風格下的多種變體,大幅提升開發效率。
在動畫和故事創作中,保持角色在不同場景中的一致性一直是重要挑戰,這項技術有望簡化流程,讓創作者更專注於故事敘述。在廣告、行銷和教育領域,也可用於快速生成符合特定品牌形象或教學需求的視覺素材。
然而,正如 OpenAI 在新釋出的系統卡中坦承的那樣,更強大的生成能力也帶來了新的挑戰。報告詳細披露了多項特殊安全措施,包括聊天模型拒絕機制、提示詞阻斷和輸出阻斷等多層防護,以防止有害內容的生成。這些內部機制的公開,讓我們首次了解到頂尖 AI 公司如何在創新與安全之間尋找平衡。
從全監督到弱監督,再到自監督和多模態融合,AI圖像訓練技術的演進不僅是效率的提升,更是對智能本質的重新思考。未來的AI訓練可能會進一步減少對人工干預的依賴,同時增強模型理解和創造的能力。隨著相關技術的持續發展,未來的AI圖像生成模型將更好地理解人類意圖,成為創意表達和視覺溝通中不可或缺的夥伴,而我們也將迎來一個圖像創作更加智能化和人性化的新時代。